How to Quantize an AI Model for Deployment?
Why Quantization?
Today, AI models are becoming increasingly large, creating a critical need to reduce their size for deployment, particularly for resource-constrained hardware such as edge devices. While these models are originally trained using FP32 (32-bit floating point) precision to ensure numerical stability, maintaining such high precision during inference is often inefficient and costly.
For this reason, quantization has emerged as a an optimization technique. It is the process of reducing the precision of a model’s parameters (weights and biases) and layer activations to ensure that the majority of the computation is performed at a lower precision. The benefits are twofold: the model occupies significantly less memory at runtime, and inference speed is dramatically increased.
This acceleration is largely driven by hardware like NVIDIA Tensor Cores and specialized NPUs, which are specifically engineered to perform high-speed integer arithmetic more efficiently than standard floating-point operations.
When discussing quantization, it is important to distinguish between methods that simply cast the parameters to a lower floating-point format (such as FP16 quantization) and those that fundamentally change the computational graph, such as INT8 or UINT8 quantization. This article focuses on the latter. In these cases, standard operations are replaced, for instance, a traditional convolution becomes a quantized convolution. This operation approximates the original FP32 result using integer math and additional metadata known as quantization parameters: scales and zero-points.
For those looking to deep dive into the implementation details of these mechanisms, I strongly recommend this excellent blog article: Lei Mao’s Neural Network Quantization.
Two Types of Quantization
There are two main methods when quantization an AI model: Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT).
Post-Training Quantization (PTQ)
Post-Training Quantization (PTQ) is the most “plug-and-play” approach that happen after the model training. By applying specific formulas, weights and biases are converted to integers along with their corresponding quantization parameters (scales and zero points).
However activations, are more difficult to quantize because they vary depending on the input. PTQ addresses this in two ways:
- Static Quantization: Estimating scales and zero points using pre-calculated statistics (on a sample dataset).
- Dynamic Quantization: Calculating these parameters “on-the-fly” during inference.
While dynamic quantization is more robust and accurate, it can be slightly slower during execution.
Quantization-Aware Training (QAT)
Quantization-Aware Training (QAT) incorporates the quantization process directly into the training or fine-tuning phase. By using additional layers that simulate the quantization behavior, often referred to as “fake quantization” the model’s weights are penalized to reduce the precision loss.
This method significantly minimizes the impact on accuracy, compared to post-training.
Choosing the Right Quantization Framework
Choosing the right framework is a strategic decision driven by your intended hardware deployment target.
Because most AI models are trained in PyTorch, your path is relatively fixed if you opt for Quantization Aware Training (QAT), you must remain within the PyTorch ecosystem. However, once the QAT process is complete, you can export your AI model to ONNX for broader conversions using torch.onnx.export.
If you prefer Post-Training Quantization (PTQ), the landscape opens up significantly, as most hardware-specific accelerators such as TensorRT, OpenVino, or stedgeAI offer their own optimization scripts. The limitation is that the produced quantized model will be in a specific format that cannot be easily converted to another, forcing you to main redundant quantization pipelines for different hardware targets.
To bypass this issue, using ONNX as a an intermediary is the most efficient strategy. By utilizing the onnxruntime library for PTQ, you can produce a single quantized model applicable across various accelerators. Within this workflow, choosing the right format is critical. While operator-oriented quantization replaces standard nodes (like Convolutions) with specific quantized versions, it often fails during conversion because external converters don’t always recognize these custom operators.
The superior alternative is the QDQ (Quantize/Dequantize) format, which represents quantization as a recognizable pattern of “Quantize” and “Dequantize” nodes surrounding a standard operation. This “pattern-based” approach acts as a universal language. Hardware converters can easily identify these patterns to map them to their own optimized implementation, while onnxruntime simply maps them back into custom operators at execution time.
Differences between operator-oriented and QDQ format in ONNX :
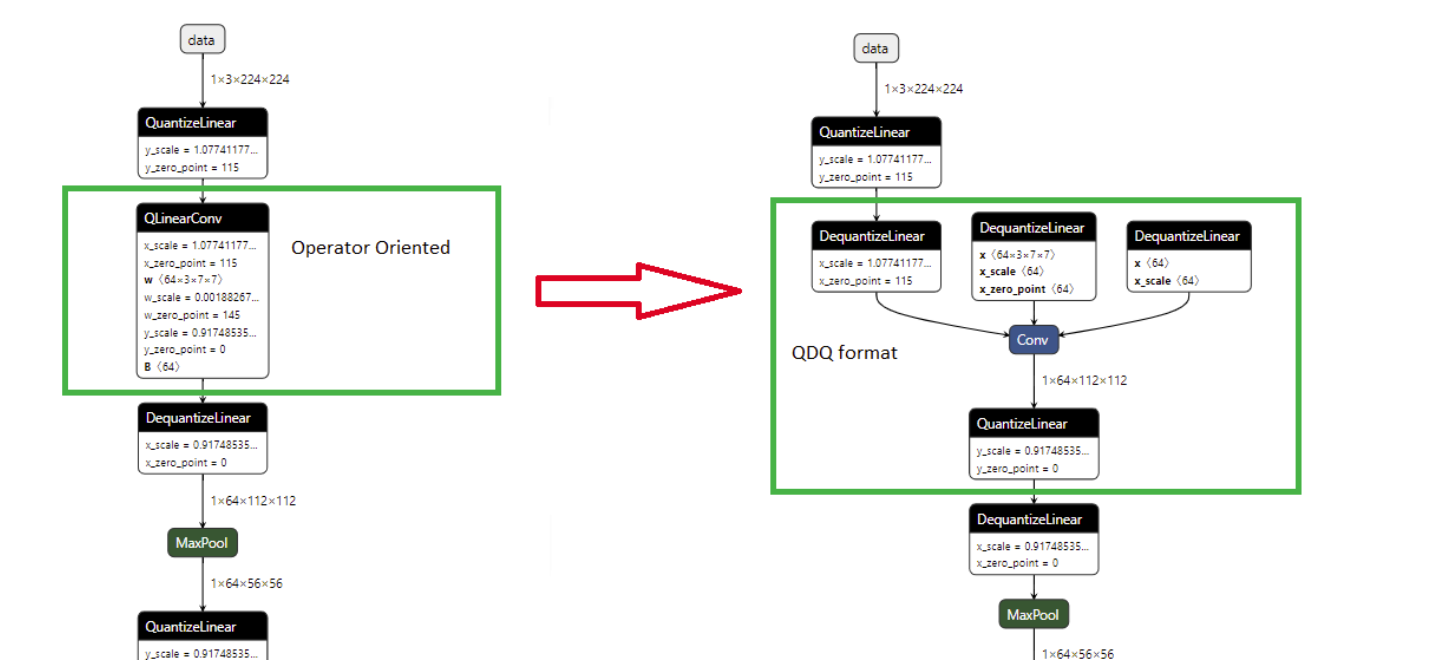
Useful Details About Onnxruntime
When using onnxruntime, the choice of GraphOptimizationLevel determines how the nodes are handled at runtime.
-
ORT_DISABLE_ALL: Performs operations in FP32 by executing the Quantized and Dequantized nodes literally. -
ORT_ENABLE_EXTENDED/ORT_ENABLE_ALL: Fuses the Quantized and Dequantized nodes into operators
Moreover, the optimized_model_filepath variable allows you to save an onnx graph that corresponds to what will be exectuted at runtime.
import onnxruntime as ort
# Initialize session options
sess_options = ort.SessionOptions()
# Define optimizations (run FP32 or int8)
sess_options.graph_optimization_level = "ORT_ENABLE_EXTENDED"
# Save an intermediate onnx model (operations performed at runtime)
sess_options.optimized_model_filepath = "runtime_onnx_model.onnx"
# Create session for the model
session_original = ort.InferenceSession(
"mymodel.onnx", sess_options=sess_options)
Why Quantization Is Not a Security Mechanism?
It is a common misconception that quantizing a model for deployment provides an inherent layer of security against adversarial manipulation. The logic seems sound at first glance: by converting weights from high-precision floating-point numbers to discrete integers, you effectively “break” the gradient flow. Since the model is no longer differentiable in its deployed state, an attacker technically cannot perform traditional white-box attacks that rely on backpropagation.
However, quantization is far from a robust “masking” strategy. While the model may not be directly trainable, an attacker can easily reconstruct the original FP32 parameters by combining the integer values with the associated quantization scales and zero-points. This estimation process is easily automated, allowing an adversary to build a “proxy” model that can be attacked.
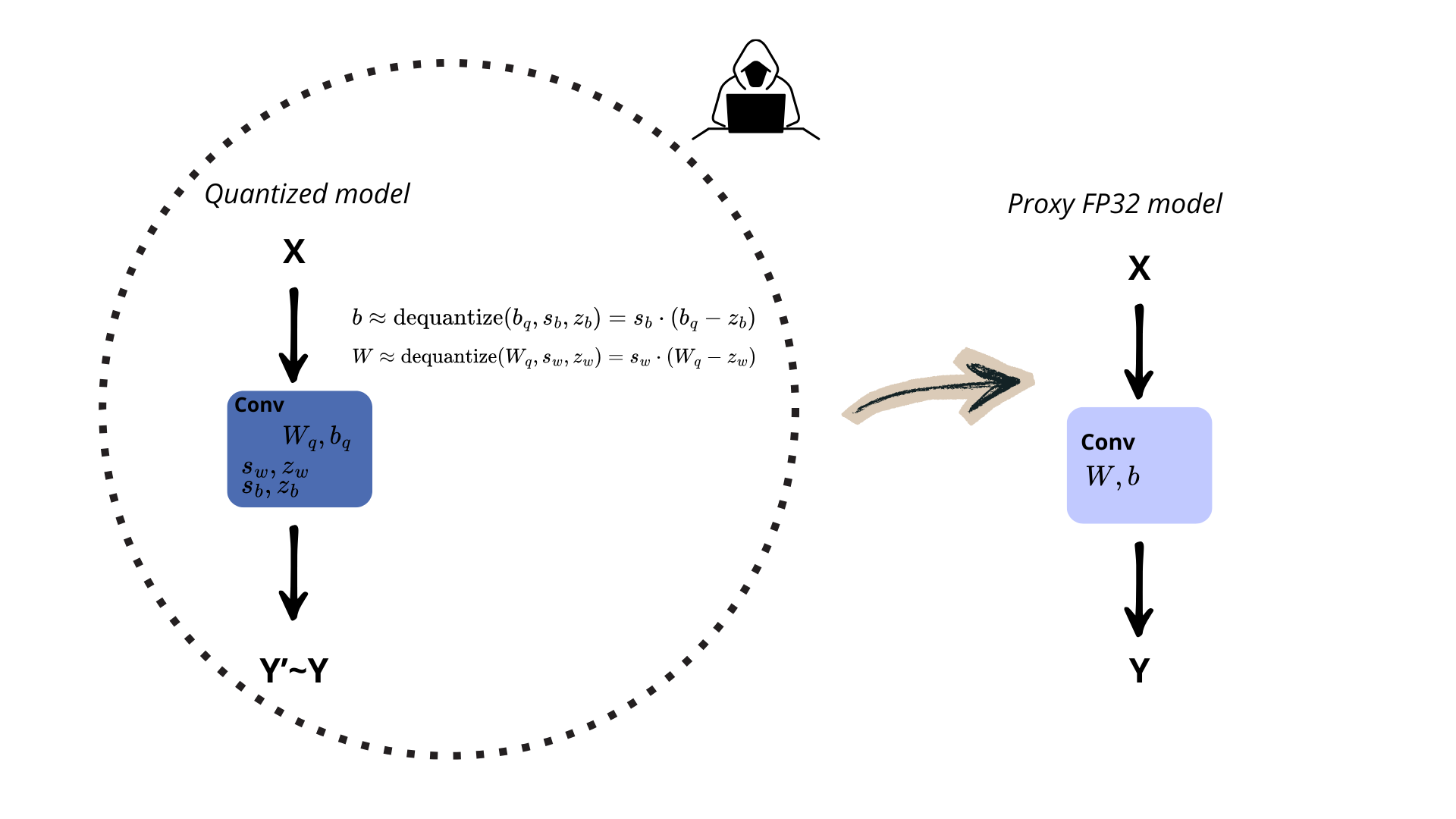
At Skyld, we demonstrated this through a practical use case, where we successfully attacked a quantized on-device Google AI model: Safetycore attack
How to Protect a Quantized AI Model From Extraction?
To truly protect your intellectual property, the focus must shift from the weights themselves to the quantization parameters. If an attacker cannot access the specific scale factors and offsets used during runtime, they cannot accurately reconstruct the original FP32 parameters required for a gradient attack.
To address this gap, Skyld proposes an AI protection that include specialized mathematical transformations designed to keep these quantization parameters confidential at rest and during the execution. Our solution is built to integrate easily into existing workflows, supporting any ONNX AI model quantized in the QDQ format.




